以前、BigQueryでクローラーの回遊URL抽出と分析では、サーバーのアクセスログからGoogleクローラーログを抽出し、分析する方法を紹介しました。
BigQueryを利用すれば膨大な生ログからGoogleクローラー(Bot)のみを抽出し、クローラーがアクセスした日時やアクセス回数(頻度)を簡単に解析できます。クローラーアクセスの解析結果から、インデックス化率が低いサイトの要因分析やページ更新頻度の向上施策の立案などが出来るようになります。
BigQueryを使う事で膨大なアクセスログ解析は簡単になりますが、それでも工数はかかるものです。
そこで今回は、GoogleアナリティクスでGoogleクローラーのアクセスを解析する方法を紹介します。普段使い慣れたGoogleアナリティクスを利用する事で、手軽に素早くログ解析が出来るようになります。
※本施策のネタ元は、deepcrawlのUsing Google Analytics to Track Googlebotを参考にしました。
Googleアナリティクスでクローラー解析する方法
それでは早速Googleアナリティクスを使ってクローラーの解析をしてみましょう。
通常のGoogleアナリティクスではクローラーアクセスが集計されない理由
通常、Googleアナリティクスでは検索エンジンやBotなど非ブラウザによるアクセスはカウント(データ収集)しません。
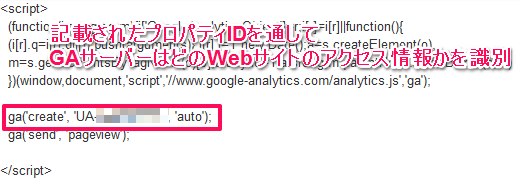
各Webページに設置されたトラッキングコードはJavaScriptで実行され、プロパティIDやリファラー情報などをGoogleアナリティクスのサーバーにビーコン(送信)します。

今でこそGoogleBotはJavaScriptを実行し、CSSを読み込み、ページをレンダリング出来るようになっていますが、以前のGoogleクローラーはJavaScriptの実行は出来ませんでした。
恐らく他の検索エンジンクローラーや情報収集クローラーも同様にJavaScriptをページ読み込み時に実行していないと想定されます。
トラッキングコード内に記述があるJavaScriptを実行しなければ、Googleアナリティクスサーバーに情報は送信されない為、クローラーのアクセス記録は残りません。
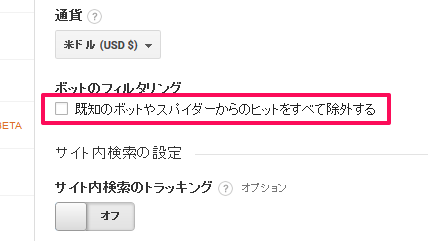
又、noscriptで囲まれている箇所を読み込み、imgなどを通してクローラーアクセスを直接Googleアナリティクスサーバーに送信した場合でも、既に知られているクローラーであればUserAgentやIPアドレスなどを元にフィルタリングし、集計対象から除外する機能がGoogleアナリティクスにはあります。
↑Googleアナリティクスのビュー設定から、既知のクローラーやスパイダーを除外する機能がある。
以上、通常のGoogleアナリティクス設定(タグ設置)ではクローラーやスパイダーのアクセスを集計する事は出来ません。
GAでGoogleクローラーのアクセスを集計するには
通常のトラッキングコードを設置する方法ではGoogleBotのアクセスを集計する事はできません。
そこで利用するのが、Googleアナリティクスの「Measurement Protocol」です。
Measurement Protocolとは、Googleアナリティクスのトラッキングを直接呼び出す為のプロトコルの事で、直接GoogleアナリティクスのAPIを読み込む事により、Googleアナリティクスにクローラーのアクセスログを保存する事が可能です。
トラッキングコードを設置できない環境でもAPIを直接読み込む事でデータを保存する事が出来る為、Googleアナリティクスを使って様々なデータの保存先や解析先として利用する事が可能です。
例:メルマガ開封率をMeasurement Protocolで調べる
今回の手法を利用するには、アクセスしてきたブラウザ(Bot)の情報を解析し、Googleクローラーによるアクセスか否かを判定する必要があります。
Googleクローラーによるアクセスと判断できた場合、エンドポイントのURLに必要な情報を乗せcURLで読み込む事で、クローラーのアクセス情報のみをGoogleアナリティクスのサーバーに送信できます。
パラメーターの値
Measurement Protocolを使って、Googleアナリティクスにクローラーのアクセス情報を送信してみましょう。
Googleクローラーのアクセスを解析するにあたり、今回は下記の通りに設定しました。
ページタイトル名にUserAgentが表示されます。又、BotがアクセスしたページのURLをdp=で渡しています。
※公式のガイドページに分かりやすく説明されています。
Googleクローラーを識別する方法
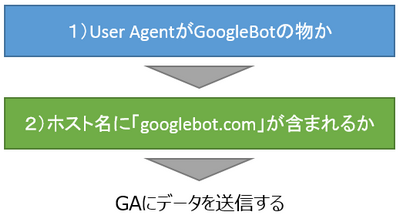
現在のところ、Google社はクローラーの正確なIPアドレスを公開しておらず、IPアドレスでクローラーか否かを判断する事はできません。そこで利用するのがUserAgentです。
Googleの公式ページにも記載がある通り、Web検索向けのGoogleクローラー(Bot)は、「Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)」をUserAgentとして利用しています。
アクセス元のUserAgentと「Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)」が一致した場合、Googleクローラーによるアクセスとして認識します。
しかしながら、UserAgentはGoogleクローラのものでも、本物のGoogleクローラでは無い事もあります。
Fake Googlebot Activity up 61% [Report]にも記載がある通り、Googleクローラと偽装したスパイダーによるアクセスが年々増加しており、その多くはDDOS攻撃やデータの収集(スクレイピング)を行っているBotとの事。
正確なクローラーのアクセスデータを収集するには、UserAgentの他にアクセス元ホスト名も確認します。
GoogleのヘルプページGooglebot かどうかの確認にも記載がある通り、クローラーのアクセス元ホスト名のルートドメインは「googlebot.com」になります。
対象ページにリクエストがあった際、UserAgentでフィルターを掛け、更にアクセス元ホスト名のルートドメインが「googlebot.com」であるかを確認します。
GoogleアナリティクスのGUI画面でBot解析
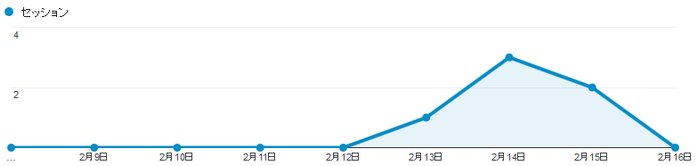
設定が完了後、クローラーのアクセスデータが貯まると、Googleアナリティクスの解析画面にはアクセスログが表示されます。
セッション数=クローラーのページアクセス回数になります。
日別や時間別にクローラーによるアクセス回数を計測できます。
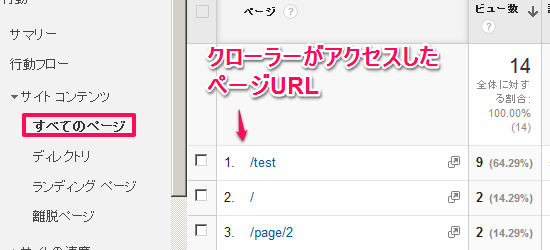
行動>サイトコンテンツ>すべてのページ を順位にアクセスします。
「ページ」に表示されるのは、GoogleクローラがアクセスしたページのURLです。ページビュー数は、各URLにクローラがアクセスした回数を表示しています。
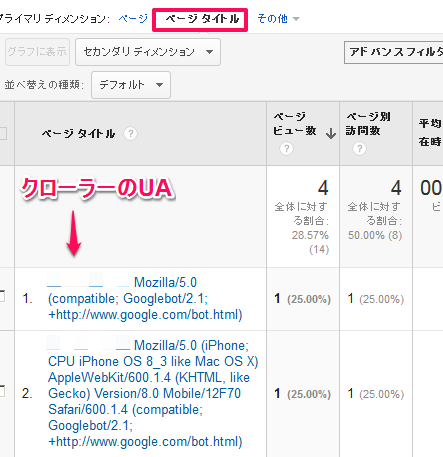
プライマリディメンション「ページタイトル」を選択すると、クローラーのUserAgent毎にページビュー数を閲覧できます。
通常のWeb検索向けのクローラのアクセスもあれば、SP向けクローラによるアクセスも確認できます。
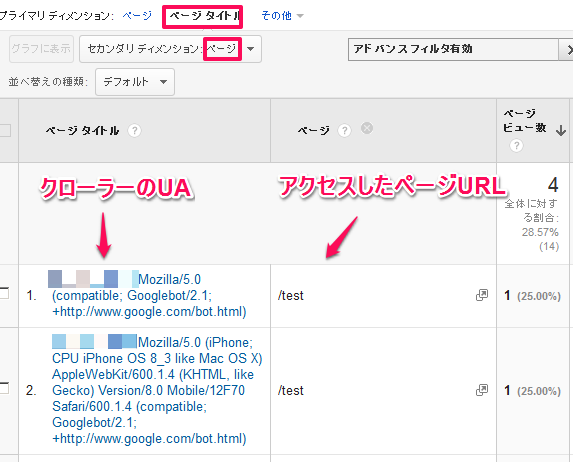
更にセカンダリディメンションで「ページ」を選択する事で、クローラのUA毎&アクセスしたページURLでデータを閲覧できます。
以上の様に、普段使い慣れたGoogleアナリティクスのGUI画面を通して、ほぼリアルタイムにGoogleBotのアクセスログを解析出来るようになります。以前の様にサーバーのアクセスログをわざわざ取得し、膨大な生ログからクローラのみのアクセスを抽出、集計する手間も不要になります。
大規模サイトを運営し、特定の下層ページなどのインデックス化率が低い場合、Googleアナリティクスを活用してクローラーの回遊頻度を分析し、その要因を探してみると良いでしょう。