多くのページがインデックス化されない事は大規模サイトにとっては大きな損失であり、SEO施策上改善しなければなりません。
インデックスされない理由は様々な為、改善には「なぜインデックス化がされていないか」という要因を分析する事から始まります。分析でよく用いられるのがGoogleBotが回遊しているページや構造を把握するアクセスログ解析です。
アクセスログの場合、GoogleAnalyticsの様にGUI画面から欲しいデータを簡単にダウンロードする事はできません。サーバーの膨大なログから必要となるデータのみを抽出しデータを形成する、といったデータ作りから行わなければならず、どうしてもエンジニアの協力が必要となります。

エンジニアの方も他の仕事がありますので、マーケティング担当者の方も何度も細かいデータ抽出を依頼できず、結局分析が後回しになってしまう…というケースもあります。しかし、GoogleのBigQueryを利用すればエンジニアリング無しでローデータからサクッと分析に必要なデータを抽出できます。
今回は、Google Big Queryを利用したクローラーログ解析を説明したいと思います。
Webサーバーのアクセスログを取得する
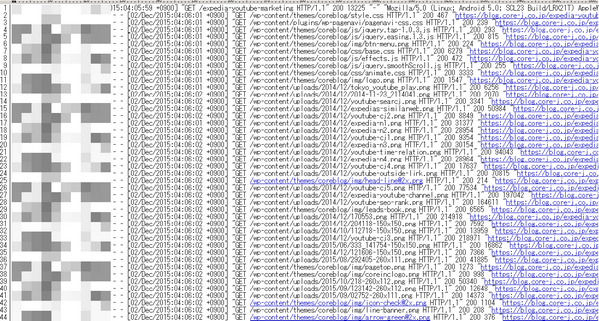
ローデータ(生ログ)となるアクセスログをWebサーバーから取得します。サーバーの設定などによってアクセスログの保存先は事なりますが、一般的なサーバーの場合は下記の通りです:
●Apache:httpd.confの「CustomLog “logs/access.log”」
●nginx:nginx.confの「/var/log/nginx/access.log」
↑アクセスログ:アクセス時間やURL、UserAgent等が記述されている
BigQueryでサクッとBot回遊したURLのみを抽出してみよう
まず例として、今回分析するWebサイトが大手ショッピングモールとします。
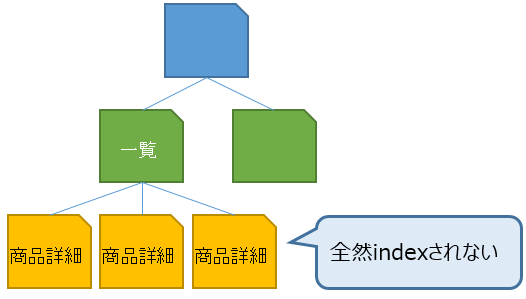
日々新しく追加される商品詳細ページのXMLサイトマップを送信しているにも関わらず、インデックス登録率が40%と低い状況が1年ほど続いています。かたや、特定のショップ配下やカテゴリ配下にある商品ページ群はオーガニックアクセス数も多いため、単に商品詳細ページ全てがインデックス化率が低いという訳ではありません。
デイリーで更新されるXMLサイトマップは、サーチコンソールの処理日を見ると2~3日間隔で処理されている事からGoogleBotはURLの認識はしているようです。
本来は、ショップ単位でXMLサイトマップが分かれていたらショップ毎の商品登録内容によってインデックス登録率の差分をサーチコンソールで確認できますが、あいにくXMLサイトマップは何の区分ルールも無く、新しい商品が追加された順番で生成されている様です。
そこで、はじめに下記を抽出しようと考えます:
抽出1:直近1ヶ月間にGoogleBotがアクセスしたURL
商品詳細ページをまとめているディレクトリ「itemdetail」配下のページに対してクローラーのアクセス数を調査しようと考えています。
もし、特定のURLしかアクセスしていない場合、アクセスしたURL(ページ)とそうではないURLの違いを探す事で要因が見つかる可能性が高いと考えました。
又、アクセスしたURLのindex化率を調べ、そもそも回遊しないからインデックス登録しないのか、それともコンテンツに要因があるのか特定できる可能性があるとも想定できます。
抽出2:URL毎のクローラーアクセス回数
そもそも全てのURLに対して均等かつ定期的にアクセスしているのでしょうか?もし特定のページ群のみ頻繁にアクセスし、逆にあるページ群には殆どもしくは全くアクセスしていない場合、それらのコンテンツやサイト構造の違いはあるのでしょうか?
又、クローラーが優遇してアクセスするページと実際の検索順位やオーガニック経由のランディングアクセス数に相関性は見られるのかも確認したいところです。
□■
以上大きく分けて2つの内容を抽出します。1つはGoogleBotがアクセスしたURLのみをディレクトリ /itemdetail/ 配下で抽出する事、そして2つ目は各URLのGoogleBotのアクセス数です。早速Google BigQueryを使って必要となるデータを抽出していきます。
BigQueryとは、大規模なデータを高速で分析するGoogle社のクラウドサービスです。Excelでは到底扱えない膨大なレコードを高速で処理し、欲しい集計データをWebブラウザ越しから簡単に抽出できます。
SQLライクのコマンドで扱える為、エンジニアリングスキルが無くても一定のコマンドを覚えるだけでデータをまとめたり、抽出、分析する事ができます。
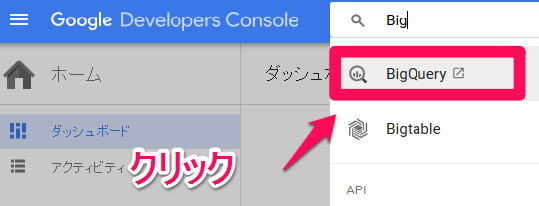
Google APIのコンソールにアクセスし、BigQueryと検索します。すると、BigQueryの管理画面URLが表示されるので、クリックします。
「Create New Dataset」をクリックし、新しいデータセットを作成します。
データセット名を記入し、ローケーションをとりあえずUSを選択します。
作成したデータセット内にテーブルを追加します。「Create New Table」をクリックします。
テーブル名を記入し、「Next」をクリックします。
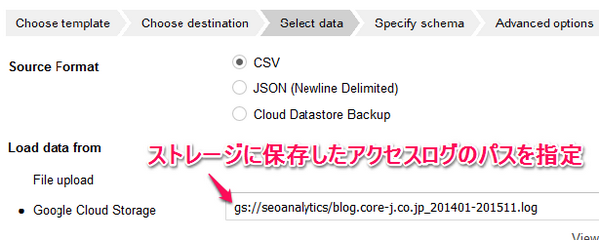
次にアクセスログデータをアップロードします。
Webブラウザ上からもアップロードできますが、10MB以下のデータしかアップロードできません。
大規模サイトのアクセスログの場合、10MBでは収まらない為、Google Cloud Storageにデータを保存し、BigQueryに送る必要があります。
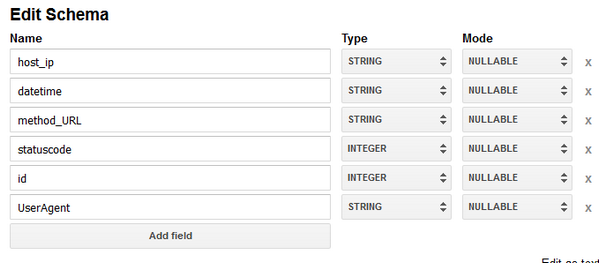
フィールド名・データ型を指定します。
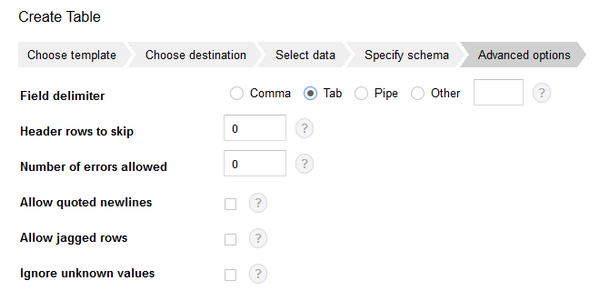
最後にローデータの区切り位置やヘッダー有無の指定を行い、完了です。
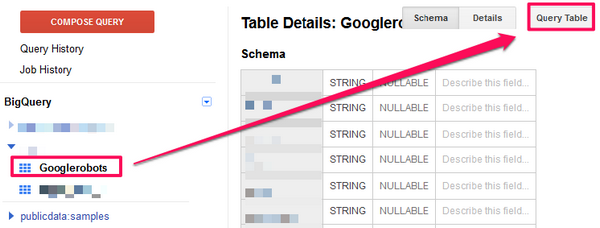
対象となるテーブルをクリックし、右上の「Query Table」をクリックします。
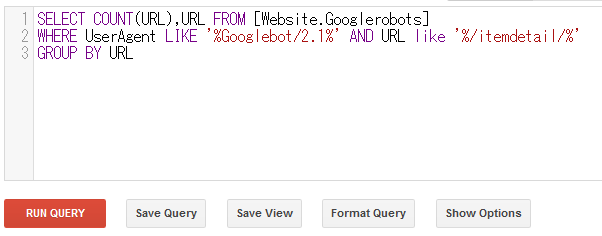
ここで欲しいデータを含むレコードを選択するQueryを実行します。
上図の例では、UserAgentに「GoogleBot/2.1」を含み、尚且つURLに対象ディレクトリである「itemdetail」を指定し、抽出しています。又、Count()で各URLのクローラーがアクセスした回数を算出しています。
MySQLやAccessといったデータベースソフトでも同様の抽出はできますが、BigQueryの良い所は割りと簡単かつ短時間でテーブルを作成できます。
又、インデックスを張る事なくフルスキャンで検索しても非常に短い時間で目的のデータを抽出できる為、SEO分析の為にわざわざデータベースを作る必要も無く、サクッと膨大なアクセスログからGoogleBotがアクセスしたURLのみを選択する、といった作業にも向いているのではないかと思います。
その他にも様々なクエリがあるので、ディレクトリ毎や商品ID別、ページ追加日時別、日別にクローラーアクセス数を集計し、GoogleBotの動きを様々な角度から分析する事もできます。
参考
・BigQueryで使えるクエリをまとめてみた
・Google クローラのUserAgent一覧
次に、クローラーが回遊したURLをCSVとしてダウンロードします。
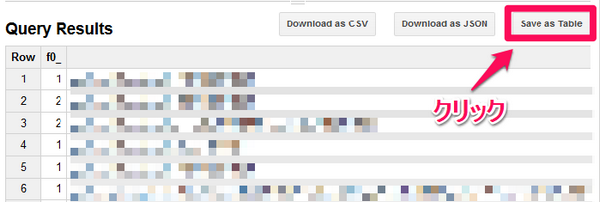
クエリを実行した状態で、これらデータのみを別のテーブルとして保存します。右上の「Save as Table」をクリックします。
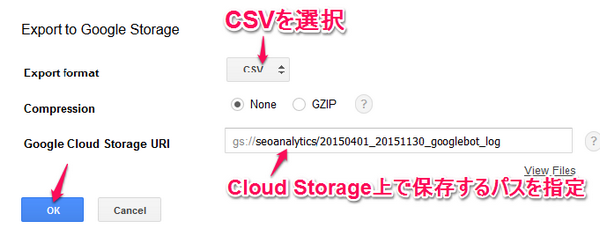
ファイル形式「CSV」を選択した上でGoogle Cloud Storage上で保存するパスを指定し、「OK」をクリックします。
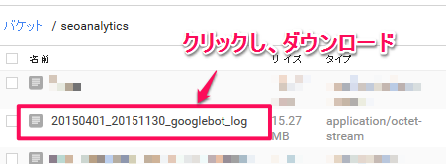
Google Cloud Storageのコンソールに先程指定したファイル名でファイルがアップロードされていますので、クリックしダウンロードしましょう。
これにて膨大なアクセスログから必要となるディレクトリ配下でGoogleBotがアクセスしたURLを抽出できました。
Bot回遊済URLリストから実際にどの様な分析をするか
アクセスログからBigQueryを用いてGoogleBotのみがアクセスしたURLのみを抽出しましたが、このリストでどの様な分析ができるのでしょうか。
まずはURL単位でインデックス有無を調査する
GoogleBotが直近n日以内にアクセスしているURLであれば、Googleはページの存在を認識しているはずです。
本来であれば全てのページがインデックスされるべきですので、Botが回遊したURLのインデックス有無をURL単位で調べてみましょう。info:を使って検索にかけ、ヒット数が1件であればインデックス済、0件であればインデックス無しと判断できます。
大半の場合、インデックスされるページ群とされないページ群では一定のパターンや共通点が見つかります。例えば、「インデックス登録されているページの多くがyyyy年mm月以降に登録されたページ」など共通点を探していくと、インデックス化されない要因が見えてきます。
その他重複コンテンツや不要インデックスの発見には、コピーチェックのAPIを利用するとよりスピーディに行えます。インデックス登録されないページのコンテンツのみをDBから抽出し、APIにデータを投げます。他ページと類似している可能性が高い場合、コンテンツの重複がインデックス化率を下げている要因と判断するヒントにもなります。
参考:コピーチェック投稿・結果取得APIのご案内
クローラー回遊頻度の違いを分析する
同じ階層にあるページでも、Googleクローラーがアクセスしてくる回数が異なるケースがあります。
特定のページ群のみGoogleクローラーが何度もアクセスしてくるページは、他ページとどの様な差があるのかを調査分析すると、各ページの評価(順位や流入など)の違いが見えてきます。その「評価違い」は、今後のSEO戦術にのヒントにもなります。
▼回遊に影響すると思われる施工・行動
・当該ページを頻繁に更新している
・当該ページにはDB内の定形データのみならず、オリジナルの説明文を入れている
・当該ページは訴求を高めたtitle文を記述している(一つ一つ手動で入稿)
・当該ページは公式FBアカウントでウォールに流している
・当該ページのソーシャル流入が多い
▼結果的に受けた評価指標
回遊が多いページとそれ以外のページの:
・サーチコンソール上での平均CTRの差
・流入時の平均滞在時間、直帰、平均PVの差
・自然検索流入の差
・主軸ワードの順位の差
大規模サイトのページ単位分析であれば、GoogleAnalyticsのAPIを利用する事で、URL単位の自然検索流入数や直帰率などの値を半自動的かつ大量に取得できます。
要因はページにGoogleBotがアクセスしていないから?
数百万ものページ数を保有する大規模サイトの場合、一つ一つページ単位でインデックスされない要因を目視チェックする訳にはいきません。大半のサイトは階層毎に同一のシステム構造となっている為、noindexの出力ミスや不要(重複)インデックスはパターンを把握すれば改善点は簡単に見つけることができます。
しかし、テクニカルSEO施策やミスの修正は施工済みなものの、なぜかインデックス化が進まないケースが大規模サイトにはよくあります。その際には、Webサイトに関する情報を元に、インデックス登録されない理由(要因)に近づいていく様な分析手法が有効かと思います。そのひとつとして今回のクローラーアクセス解析が挙げられます。
●よくあるインデックスされない要因例:
- ページ内容が他ページと重複している(重複コンテンツ)
- ページ内容が低品質コンテンツである
- そもそもクローラーが回遊していない・出来ない
- meta noindexやcanonicalが誤って記述されている
SEOを企業の重要施策として行っている場合、不要インデックス(重複コンテンツ)の排除やGoogleBotの回遊導線確保(XMLサイトマップや内部リンク等)など、テクニカルSEO施策はほぼ施工済のケースが大半です。
そのような状態にも関わらず、インデックス化が進まない要因としてクローラーアクセスに問題があると考える事が出来ます。
Googleのクローラー(Bot)が下層ページにアクセスしていない、もしくはアクセス出来ない事により、インデックス登録させたいページをGoogleが認識すらしていない可能性が挙げられます。
もし、クローラーがアクセス出来ていないのであれば、「なぜアクセス出来ないのか」という要因を解明しなければ解決には至りませんが、その仮説が正しいか否かを分析する事がまず最初のステップになります。
参考:
・サイトの検索時の掲載結果を確認する
・クロールされない、または Google のインデックスに登録されないページがある
BigQueryを使ったログ抽出のまとめ
今回は膨大なローデータから、ブラウザ上で簡単にGoogleBotがアクセスしたURLのみを抽出する方法を紹介しました。
BigQueryを利用する事で、データベースの構築などの技術を必要とせず膨大なアクセスログからBotアクセス済URLのみを抽出する事ができます。
BigQueryはビッグデータを解析・分析するツールなので、単なるデータのフィルターとしての機能として利用するのみならず、回遊数やアクセス数、順位、表示回数など他データと付きあわせて分析してみると、今まで見えてこなかったGoogleBotのクローリンパターンや順位との相関インサイトが見えてくるかもしれません。
尚、BigQueryは従量課金制なので、くれぐれも使いすぎにはご注意を。
└BigQueryで150万円溶かした人の顔