先日、米シアトルで開催されたSMX Advancedという検索エンジンマーケティングに関する世界的なカンファレンスにて、Googleのレンダリング能力が向上したと発表がありました。
参考:海外SEO情報ブログ:Googleのレンダリング能力はここまで向上している
海外SEO情報ブログの記事によると、現在GoogleBot(クローラー)はブラウザ並にレンダリングできるようになっており、コンテンツの「表示」によっても各コンテンツを評価している、との事。
これにより、アコーディオンパネルなどで隠れるコンテンツの重要度を下げて評価出来るようになったり、JavaScriptをフルに実行し、ユーザーが見ているコンテンツと同じ形でGoogleBotもコンテンツを取得し、ページ評価が出来るようになったのでは無いかと考えられます。
そこで今回は、レンダリングの一部であるjavascriptをGoogleがどの様に実行し、ページのインデックスや評価に繋げているか検証してみたいと思います。
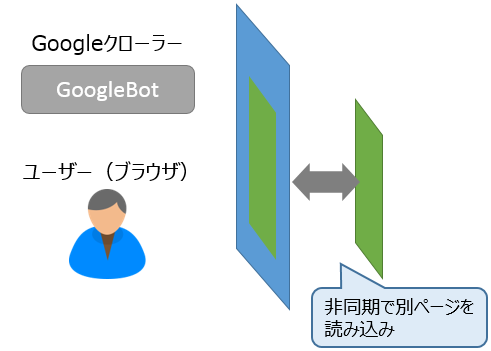
別ページを非同期で読み込むページをGoogleはどう認識するか?
今回の実験では、データベースと連動する「ページネーション」を設置し、Googleクローラーの動きを見てみました。「賃貸比較サイト」をイメージとし、物件一覧ページで表示する一覧データの部分のみを別枠で読み込み、表示しました。

そのページにアクセスするブラウザ(ユーザー)やGoogleBotには1枚のページに見えますが、非同期で別ページの裏側で読み込み、表示しています。
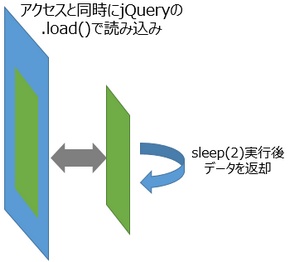
今回は検証サイトでは、jQueryの.load()でページアクセスと同時に別のページを読み込みます。読み込み先のページは2秒間経過した後にデータを返すページを作りました。
ブラウザでページにアクセスすると、読み込み箇所以外は即時表示され、2秒後に読み込みが完了し案件一覧の部分が表示されます。
さて、このページに於いて、GoogleBotはどの様な動きをするのでしょうか。気になった点を下記に書き出してみました:
●JavaScriptを実行し、読み込み先ページもGoogleBotは取得するか?
●読み込み元と先の2枚のページで構築されているが、Googleはこれを「1枚のページ」として評価するか?
●読み込み先を別ページとしてインデックスしないか?
では、実施に検証してみましょう。
【1】GoogleBotは読み込み先も正しく取得するか?
JavaScriptで非同期に読み込むページをGoogleクローラーも正しく読み込むのでしょうか?
実際に読み込み先のページ表示には2秒間のレイテンシが発生します。この時、GoogleBotは読み込みが完了するまで待ち続けてくれるのでしょうか?
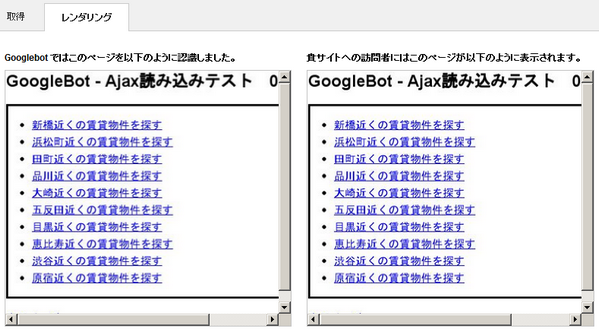
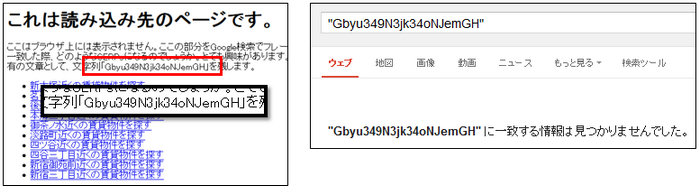
この検証にはサーチコンソールのFetch As Googleを利用しました。Fetch As Googleでは、GoogleBotがWebページをどの様にレンダリングしているのか視覚的に確認できます。
上図は今回の検証ページのFetch as Googleの結果画面です。左側がGoogleBotが認識したレンダリング後のページであり、右側が実際にブラウザで表示した時のレンダリング結果です。
FaGの結果を見ると、JavaScriptで読み込む箇所をGoogleBotも正しくローディング出来ているようです。2秒間のレイテンシがあっても最後まで読み込んでいる事もFaGの結果から分かりました。
【2】読み込み先ページは別途インデックスされるか?
読み込み先のWebページは、個別のURLで独立して存在します。GoogleBotが読み込み先ページのURLを認識しアクセスしているのであれば、その読み込み先ページも個別でインデックスされる可能性は無いのでしょうか?
もしインデックスされる事になれば、サイト内での重複を生み出す結果となりかねません。
読み込み先ページには固有の文字列を予め記載し、インデックスされた時にその文字列でヒットするか調査出来るようにしました。検証する全ページがインデックスされている中、この固有文字をフレーズ一致指定で検索した所、何もヒットしませんでした。
試しに site: で読み込み先ページのURLを検索しましたが、インデックス化はされていませんでした。
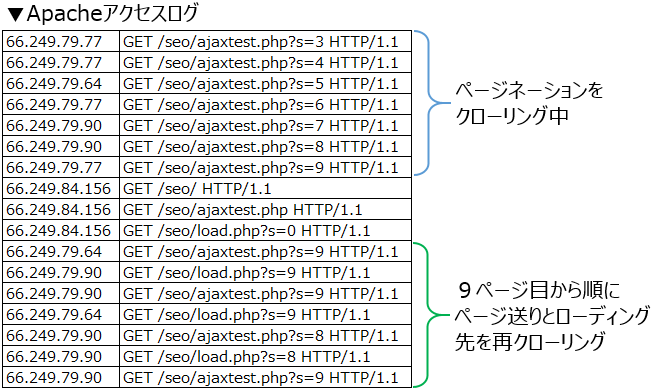
尚、Apacheのアクセスログを見てみると、Googleクローラーは読み込み元となるページネーションをクローリング後、読み込み先であるload.phpへもアクセスしている事が分かります。
以上を見る限り、個別のURLをBotが見つけたからといって、Googleが全ページをインデックス対象としている訳ではなさそうです。
Googlebotのレンダリング能力の強化によって、これら読み込み先として機能するパーツ的ページもBotがアクセスする事になります。もし、これらパーツ的役割を果たすページを全て個別のWebページとしてインデックス化していたら大量の低品質コンテンツが発生する可能性があります。
今回の検証では読み込み先のページは個別ではインデックスしないという事が分かりました。検証するページは10ページあり、全てインデックスされていない事をみると、Googleが意図的に判別している可能性があります。
あくまでも私の予想ですが、恐らくGoogleはこの件も考慮し、これら読み込み先ページは個別インデックス登録しないのかもしれません。
【3】ローディングしたコンテンツは、読込元ページの一部として認識されるのか?
読み込み先のコンテンツがリッチの場合、読み込む元のページコンテンツの一部として評価させたいものです。
今回の検証ページはブラウザから見ると1枚のページに見えますが、本来は2つのページで構成されている事になります。この際、読み込み先のページコンテンツは読み込み元のページ一部として認識されているのでしょうか?
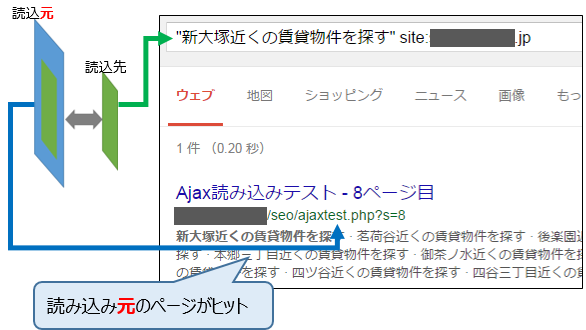
Googleで読み込み先ページにしか記載が無い文字列で検索した所、正しく読み込み元の一部として認識されている事が分かります。
レンダリングした上(ページコンテンツ表示を完了した上)で、1枚のページとしてインデックス化し、評価している様です。
今回の検証結果のまとめ
●GoogleBotは読み込み先も正しく取得するか?
⇒正しく取得する。恐らくブラウザでレンダリングできるJSであれば、GoogleBotも全く同じ様に取得&レンダリングできると思われる。念のため、Fetch As Googleの「取得してレンダリング」で確認すると良い。
又、今回の様に別のHTMLページを読み込む場合とは別に、JSONで記述された一覧データをブラウザ上でレンダリングする場合でも問題なくGooglebotは読み込み、レンダリング&評価できると想定される。
●読み込み先ページは別途インデックスされるか?
⇒今回の検証では「されない」という事が分かった。パーツ的役割を果たすページに直接内部リンクを向けたりしなければ、個別でインデックス化されないのでは、と想定される。
●読込元ページは、読込先ページの一部として認識されるのか?
⇒読み込み先コンテンツの一部として認識される。レンダリングした後にインデックス&評価されると考えられる。
最後に
今回の検証結果は想像した通りの結果となりましたが、Googleが正しくレンダリングし、その後インデックス&評価している事が実証できました。
以前はAjaxなどで他コンテンツを読み込み、表示する様なWebページを構築する場合、GoogleBot専用の別ページ(HTML Snapshot)をSEOの一環として用意する必要がありました。
参考:AJAX クロール: ウェブマスターおよびデベロッパー向けガイド
しかし、botの性能やサーバーリソースの拡充によって、GoogleBotもjavascriptの実行やCSSによるレンダリングなども出来るようになり、botを考慮したページを用意しなければならない必要性が下がっています。
ユーザーが見ているコンテンツをGoogleも同じ様に認識&理解出来るようになりつつある今、よりユーザーファーストのページ構築がGoogleからの評価向上にも直結する様になっていると感じました。
技術の進化に伴い、人間が感じる「良いコンテンツ」をGoogleも同じように認識でき始めてきている傾向では無いかと思います。