文章が他Webサイトにコピーされていないかチェックするツールを公開しました。文字数の制限があるベータ版ですが、どなたでもお使い頂けます。

コピーチェッカーの使い方
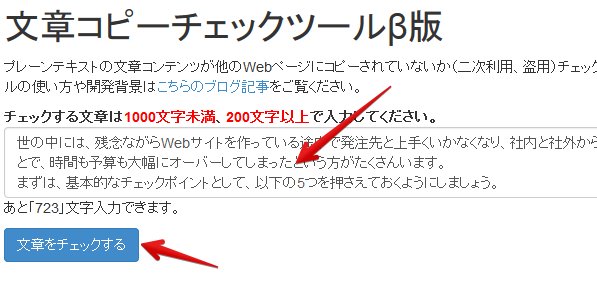
コピーチェッカーβ版にアクセスし、チェックしたい文章を入力します。
最低文字数は200文字、最大1000文字までチェックできます。長文の場合、300~400文字毎にチェックをかけた方が、精度高く検出できます。
1000文字の場合、処理が終わるまで2~3分間かかります。
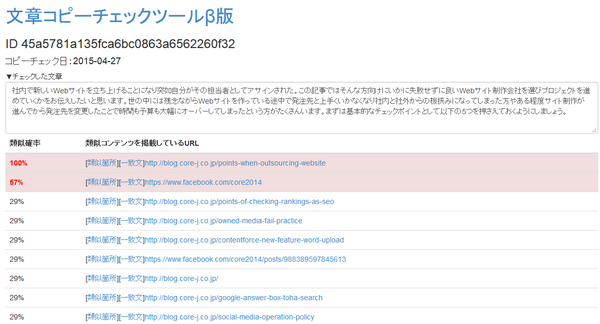
解析が終わると、上図の様な結果画面が表示されます。
コピーコンテンツの疑いがあるWebページURLと類似確率が表示されます。
各WebページURLの [類似箇所] をクリックすると、チェックしたテキストのどの箇所と一致しているのか確認できます。
[一致文]をクリックすると、一致した文章のみを表示します。各文章横にある[G検索]をクリックすると、類似コンテンツを掲載しているWebページのGoogleキャッシュページが表示され、一致するキーワードが色付きで表示されます。
▼結果画面の例
弊社ブログ記事の導入文をチェックした際の結果画面例はこちら
コピーチェッカーの利用シーン
実際にどの様なシーンでこのツールを使うと良いのでしょうか。コピーチェックツールの考え得るシーンは下記3つです。
【1】外部ライターから納品された記事をチェックする時
自社Webサイトに掲載するコンテンツを外部のライターに依頼している場合、念のためコピーチェックをかけるのが良いでしょう。
知らない所で、他Webサイトの文章をそのまま若しくは一部リライトして掲載していたという事も未然に防ぐ事が出来ます。
【2】自社コンテンツが盗用されていないかチェックする時
自社Webサイト上に掲載していたコンテンツが無断で他サイトに転載されている事をいち早く検出する事が出来ます。
反響数が多いコンテンツページや検索トラフィックを多く獲得するコンテンツを中心に、無断で盗用、転載されていないか定期的にチェックします。
【3】自社サイト内で重複コンテンツ発生していないか調査する時
SEO上、重複コンテンツや類似コンテンツはWebサイトの評価を大きく下げる要因となります。
重複が発生し易いと思われる箇所のWebページコンテンツをコピーチェックにかける事で、重複箇所を探し出す事ができます。
例:
当ブログ記事のコピーチェック
↓↓↓
[著者ページ]にもコンテンツが掲載されている。SEO上、インデックス登録が不要と思われるので、meta noindexで対処する。
開発背景
弊社ではライターとコンテンツマーケティングを実施する企業を繋げるプラットフォーム「ContentForce」を運営しております。面接や課題提出など厳格な審査を通過した質の良いライターのみが参加しているのがContentForceの特長です。
クライアント企業様に記事を納品する際、コピーチェックや表現統一、NGワードのチェック、校正、校閲、編集など様々な工程をえて納品します。これらチェック工程は非常に時間を要します。文章(コンテンツ)の品質向上には人間のみが出来る校閲や編集に最大限時間を割く体制づくりが必要であり、自動化できるチェック項目を出来る限り自動化しようと取り組んで参りました。その一つとしてコピーチェックがあります。
以前は、市販のコピーチェックツールを利用していましたが、リライトや入れ替えの検出精度が弊社が求めている水準まで届いておらず、何度か手動でチェックする事がありました。又、ライターから納品されてから数日後にチェックし、一部抜粋箇所の修正を依頼するといった数日間のブランクが発生する事もありました。
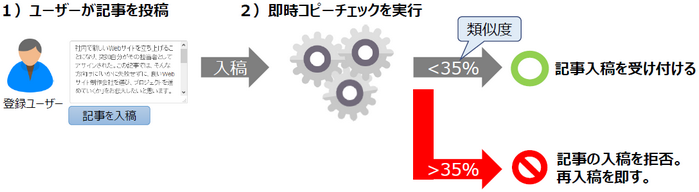
現在は、ライターから納品された直後にコピーチェックが作動し、自動的にチェックします。一定の基準を超える場合は、その場でライターへの修正依頼が入ります。これにより、精度高く、早く検収する体制を構築しています。
コピーチェック検出範囲と精度
チェック範囲
Web上で閲覧できる全てのコンテンツがチェック対象となります。
ファイル形式は問わず、PDFやWord、Excel、Text、HTMLなど文章を文字データとして表示できるファイルは全てコピーチェック対象となります。
コピー検出精度
完全な複製はもちろんの事、語尾を変えた文章や並び順がオリジナルとは異なる入れ替えが発生した文章、大幅にリライトした文章までオリジナルから原型を留めなくても、検知可能です。
以下、検知精度のテスト結果:
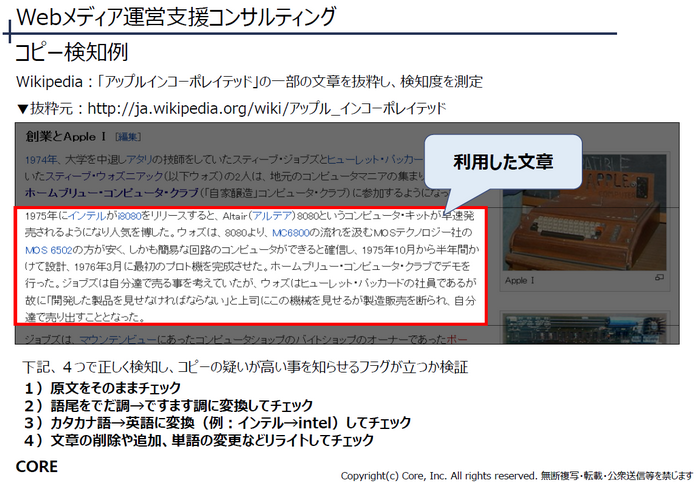
Wikipediaのアップルインコーポレイテッドから一部文章を抜粋し、下記4つの形式で正しくコピー検出できるかチェックしました。
1)原文をそのままチェック
2)語尾をでだ調→ですます調に変換してチェック
3)カタカナ語→英語に変換(例:インテル→intel)してチェック
4)文章の削除や追加、単語の変更などリライトしてチェック
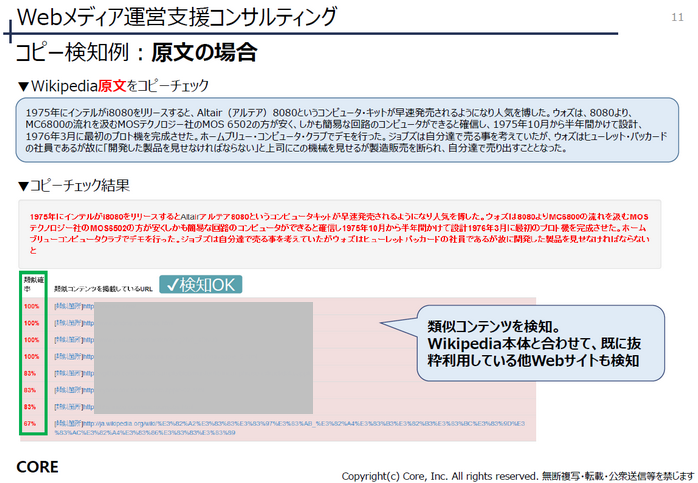
原文をそのままコピーチェックにかけた場合の結果です。
オリジナル元であるWikipediaはもちろんの事、Wikipediaのコンテンツを記載している他Webサイトも検出。原文の場合は正しく検出できました。
語尾を変えた場合のコピー検出結果です。
原文は「でだ調」でしたので、全ての文章を「ですます調」に書き換えました。
コピーチェックの結果、語尾を変えても正しく検出できました。
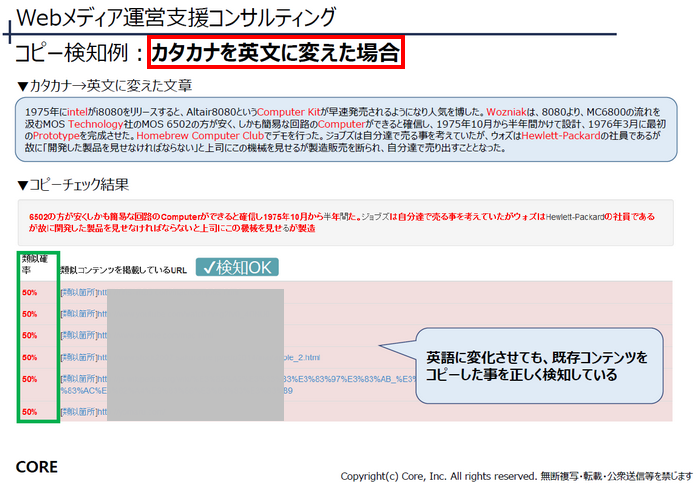
次にカタカナ語を全て英語に書き換えました。この場合でも、正しく出典元を検出できました。ある程度の単語数であれば、全く異なる物に置き換えても正しく検出できます。
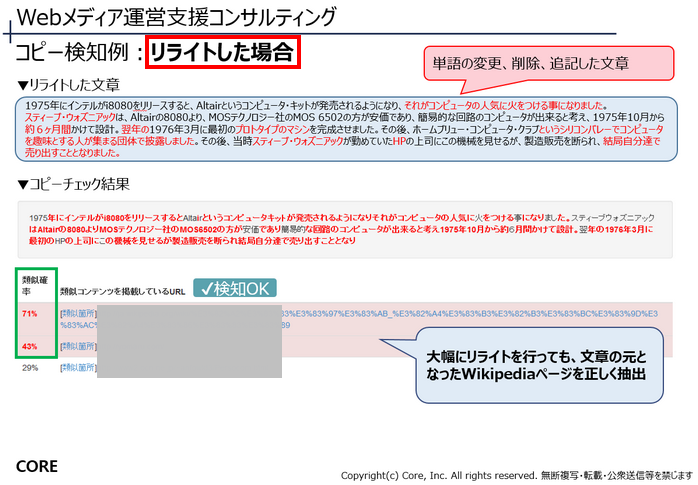
文章を大きく書き換えた場合も、正しく検知できました。
原文の主語を変えたり、言い回し方や表現などを変更し、更に追記や文章の入れ替えなども行った文も、抽出元であるWikipediaを正しく検出できました。
APIの提供を開始します
コンテンツマーケティングのコンサルティングを提供する中で、コピーコンテンツ対策をご要望の企業様に対し、当APIを提供しております。
提供方法は各メディアや企業様の用途によって異なりますが、主な提供方法として下記4つが挙げられます。
API提供型
POST形式でコピーチェックしたいコンテンツをAPIを通してCopyCheckerに投げます。数分後にコピー判定の結果を取得します。
取得できるデータには類似度(%)や類似が疑わしいWebコンテンツのURLなどが含まれます。
そのデータを元に、投稿された記事を自動的に非公開にしたり、人の目によるチェックへ渡す、meta noindexによるGoogleインデックスの登録防止などの処置を行います。
XMLサイトマップとの連動型
Googleなどの検索エンジン向けに出力しているXMLサイトマップURLを指定する事で、弊社のクローラーが記事(オリジナルコンテンツ)が掲載されているWebページのURLを取得し、自動的にプレーンテキストコンテンツを取得し、定期的に盗用チェックを行います。
事前にXPathでメインコンテンツ箇所を明確に指定する事で、本文のみをコピーチェックにかける事ができます。XMLサイトマップの要素であるLastmod値やPriority値などを利用し、クローラーの巡回先を調整する事も可能です。
URL指定型
特定のWebページのみを監視したい場合は、CopyCheckerの管理システム側に対象となる巡回先URLを登録しておきます。
チェック間隔を毎週、毎月、3ヶ月毎に指定し、自動的にクローラーが対象コンテンツを取得させ、コピーチェックします。
疑わしい盗用Webページが見つかった場合は、指定したメールアドレスにアラートメールが届きます。
コンテンツ文章保存型
チェックしたい文章をCopyCheckerのシステムに保存し、チェック間隔(1回のみ~3ヶ月毎)を指定します。
コピーを検知した場合、メールで通知します。
—
その他、カスタマイズする事で、韓国語や中国語、英語など外国語のコピー検出もできます。
詳しい仕様や金額に関しては株式会社Coreまでお問い合わせください。