SEMや言語解析などを行っていると、自ずとキーワードデータが溢れてくると思います。
GoogleおよびYahoo!のHTTPS化によって流入キーワードのデータは取得できなくなったものの、依然サーチコンソールの検索アナリティクスデータやキーワードの検索順位データなどを用いて、キーワード単位のパフォーマンスを計測する事が可能です。
又、PPCに於いても自動抽出したキーワードやクエリを基に広告を出稿する事ができますが、大量のワードを適切に広告グループ化しなければ広告を正しく調整する事が困難になります。
今回は、出来る限り人の手を使わずキーワードのテーマや意味単位でグループ化する方法を検証してみました。
大量のワードを分類化する目的とは
フリーワード検索ページのSEO施策や、自動抽出による広告キーワードの生成などを行なうと、大量のキーワードデータが手元に溢れてくると思います。
広告の調整やページ単位の効果測定を適切に行なうには、膨大なワードを人間が管理・理解できるグループ単位にまとめる必要があります。

数千のキーワードであれば力技で人的に分類できますが、1万を超えると人の手による分類・グループ化は難しいでしょう。
予め策定したグループ毎に関連するキーワードを紐付ける事で、後々の調整や効果測定・レポーティングなどを簡易化かつ効果的に図る事ができます。
今後も半自動的に増え続けるキーワード(クエリ)に対応する為には、キーワードの人的精査ではなく、機械学習を用いて半自動的に精査・分類する方法が無いか調査しました。
機械学習でキーワードを分類化・グルーピングしてみる
最近話題の機械学習ですが、Amazon Web ServiceやGoogle Cloud、MS AzureなどのPaaS事業者が多くの機械学習プラットフォームを提供しており、機械学習を取り入れる難易度も大きく下がりました。
特にMicrosoftのAzureはマシンラーニングのサービスをいち早く提供しており、優れたGUI画面から直感的に処理フローを組む事ができます。
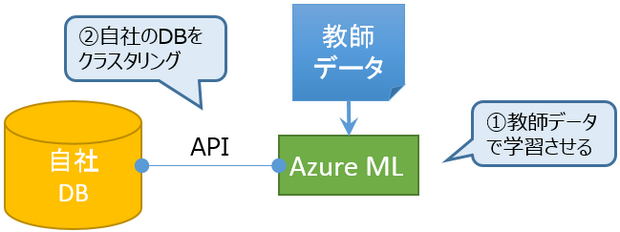
教師データを用意して機械に学習させる
予め正解となるデータ(教師データ)を用意し、機械に読み込ませます。機械は教師データを通じてパターンを学習し、自ら新しいデータを処理できるよう自分自身で鍛えます。
今回のグルーピングも正解となる教師データをAzureに読み込ませて学習させ、機械的な精査によるグルーピング精度が高まった時点でWebAPIを通してDB内のキーワードをグルーピング化させます。
以上から教師となるデータを如何に精度高く、一定数以上収集するかが第一のポイントとなります。
人によるカテゴリ紐付けから教師データを抽出する案
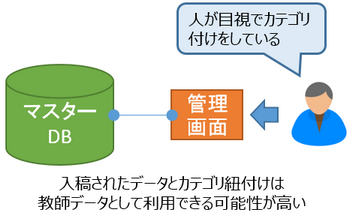
ECサイトや求人サイトなどデータベースを主体としているWebサイトの場合、入稿されるデータ(商品や求人案件)の多くは管理画面から人の手で入力されるケースが大半かと思います。
自社サイトの固定カテゴリと入稿する案件の紐付けも人間が管理画面を通して行っている為、一定の関連性(精度)は担保できていると仮定する事ができます。
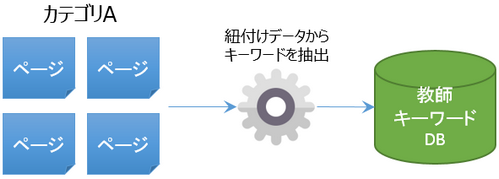
既存の固定カテゴリが一定の網羅性と数がある場合、これら既存固定カテゴリをグループとして取り扱い、既に紐付いているデータから関連ワードを抽出し、教師データとして利用できる場合があります。
各カテゴリに紐付いているデータ(案件)からmecabなどを用いてキーワードを抽出し、教師データ案として収集します。
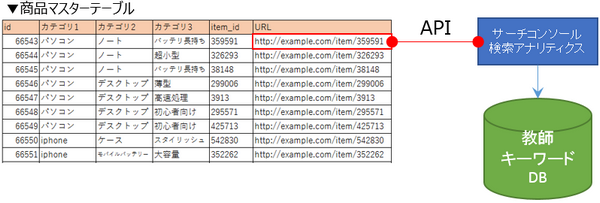
その他、サーチコンソールの検索アナリティクスも教師データの元データとして収集する事ができます。
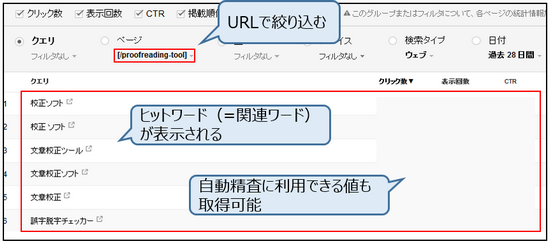
サーチコンソールでは検索アナリティクスという機能を提供しており、URL単位で検索ヒットしたクエリデータを収集できます。現在のGoogle検索アルゴリズムは極めて精度が高く、完全一致するワード以外にも関連性が高いワードでもヒットします。
マスターテーブルのURL毎にAPIを通して検索アナリティクスのヒットワードを取得し、クリック数や表示回数、順位などでフィルタリングをかけ、元データとしてDBに登録します。
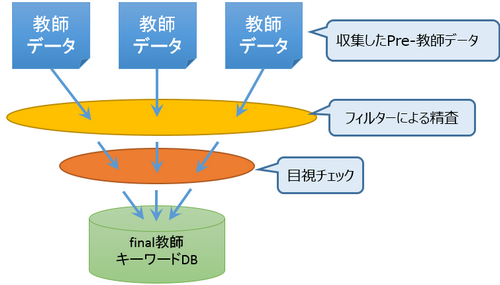
教師データをクレンジング
学習の大本となる教師データそのものが不正確な場合、当然機械学習で生成されたパターンも不正確なものになります。
NGワードや不適切なワード、検索Volなどの検索に関係する値などを利用して、フィルターによる不要ワードを排除し、その上で人間による目視チェック・修正をいれる事で、一定の品質・正確さを保持した教師データを作り上げていきます。
Microsoft Azure Machine Learningで分類分け
今回はAzureの機械学習を使ってグルーピングを行ってみました。
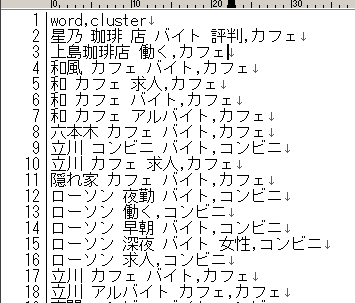
検体数は少ないですが、アルバイト募集サイトでのキーワードグルーピングを想定し、「コンビニ×アルバイト」に関するワードと「カフェ×アルバイト」に関するワードの2つのグルーピングを行ってみました。
キーワードの中には「上島珈琲店 働く」や「ローソン 夜勤」など、カテゴライズ化共通ワード「カフェ」や「コンビニ」を一切含まないキーワードも多数入れました。
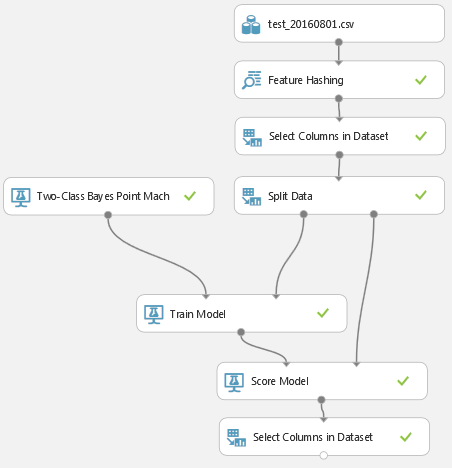
今回は、Feature Hashingを用いてパターンを学習するモデルを利用しました。
「Two-Class Bayes Point Machine」という学習モデルでパターンを学習し、ワードからグループ名を判断させます。
今回は学習用に全体の80%を、試験用(評価用)に残りの20%のデータを利用しました。
上の図は試験用に振り当てたデータに対するグルーピング結果です。
ワード単位で見ると、正解とほぼ一緒のグループ化ができているように見えます。
試しにトレーニング済のモデルに対して別のデータで自動分類化をしてみましたが、正解率は64%と手軽にできる割には高い精度であると感じました。
パラメータの設定や教師データの量、学習モジュールの再選定により更に精度は高められると思います。
APIで外部と連携する
Azure MLはWebAPIを簡単に作成でき、作成した学習モデルを外部のデータベースや既存のシステムに組込み、半自動的にキーワードデータの判別を行なう事が出来ます。
最後に
今回は簡単にAzureMLを触ってみましたが、比較的簡単に機械学習を取り入れてデータを精査する事ができました。
まだまだ精度の問題などもあり、課題はありますが、コレほどまでに簡単に取り入れる事が出来るようになった機械学習は、SEOやマーケティングに於いても工数の大幅な削減や埋もれていたデータの有効活用に大きく寄与してくれる事でしょう。
データベースに入力する商品データの紐付け自動化や、ユーザーが入力したコンテンツと既存カテゴリの自動紐付けなどSEOに於いても活用面は多数ありそうです。