Web上でビジネスの成功確度を高めるには、市場のニーズに合った商品の開発と集客数の最大化の2点が必要です。
しかし、ネット上の集客元は日々劇的に変化し、「王道の手法」と言った長らく有効に続く集客のお手本が存在しません。
例えば、一昔前にはYahoo!ディレクトリへの登録する事でYahoo!検索に優先的表示がされ、結果的に集客数の増加に大きく貢献しました。しかし、今では通常のオーガニック検索ページに表示されない為、以前のようなアクセス数の増加は期待できなくなっています。また、ここ1年の内に集客口としての地位を確立したニュースアプリの重要性も、このネット産業の移り変わりの早さを象徴するものだったりします。
以上の様に、ネット上でマーケティングをしようとした場合、過去通用した手法が今も有効だとは限らないという事です。
そこで重要になるのが現市場の調査、分析です。目標としている企業や競合のWebサイトを解析し、実態を把握します。表には出てこない数値など実態を表すデータを元に、他社の施策の効果有無を判断し、自社に取り組むべきか否かを判断します。

こうする事で、限り有る社内のリソースで、現状の市場感で成功している他社を手本に戦略・施策立案を行い、自社のビジネス成功の確度を高める事ができるのでは無いかと考えています。
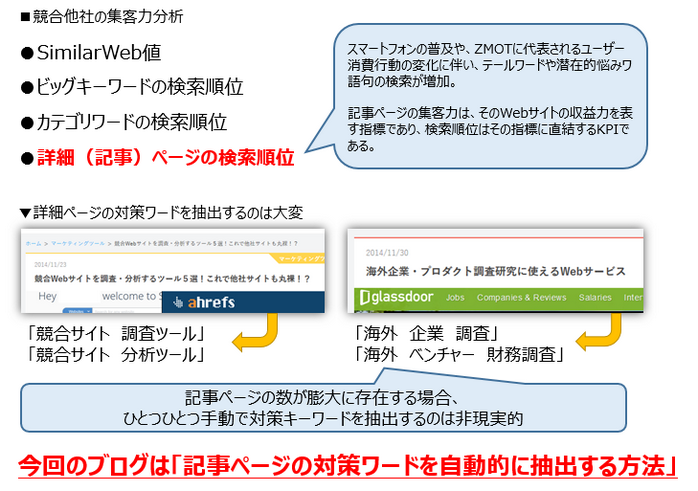
今回のブログテーマは、競合Webサイト分析のひとつである記事ページ群で対策しているキーワードの抽出手法を紹介したいと思います。
競合Webサイト分析
一言に競合ウエブサイトの解析と言っても、調べる内容や指標は多岐に渡ります。
このブログ記事では、競合分析のひとつである記事ページの順位と、キーワード(コンテンツ)テーマの分析に絞ってご説明したいともいます。
今なお検索エンジンからのアクセスはどの業態・業種でも重要であり、検索エンジンを意識したWebサイトの構築は必然不可欠です。また、最近のGoogleはWebサイトの経歴や被リンクといった従来の評価指標以上に、Webサイト内のコンテンツの充実性などコンテンツの品質を重視しており、実際の検索結果も大きく変化しました。
その上で、やはり考慮しなければいけないのが、「検索エンジンからの評価」です。そこで、今回は検索結果ページで順位を上げているコンテンツとそうではないコンテンツを調査・分析する為に必要な、記事ページで対策しているキーワードの抽出方法を紹介したいと思います。
競合サイトの記事を一つひとつ手動でかき集め、タイトル文から対策している単語をExcelに打ち込むことも出来ますが、ある程度の数(調査対象ワード数)が無いと正確な傾向が掴めない為、自動的に大量の検体キーワードを抽出しなければなりません。
では、各コンテンツページのタイトル文から対策している単語を抽出してみましょう。
調査までのステップは大枠上図の5つに分ける事ができます。
大量のタイトル文を抽出する
まずはじめに、調査したいWebサイトのコンテンツページ(最下層にあるページ群)のタイトル文を集めます。
一つひとつ対象となるWebページにアクセスしtitle文を抽出する事も可能ですが、今回は被リンク調査ツールであるAhrefsのCrawl Reportを利用して、一気にダウンロードしてしまいます。
※Crawl Reportは有料メンバーのみ使用可能
Screaming FrogやWeb explorerなどデスクトップアプリケーションのクローラーとは異なり、Ahrefsが事前にクローリングしたデータの中から欲しい箇所のみのデータを待ち時間なく直ぐにダウンロードする事ができます。
デスクトップ型クローラーの場合、短時間の内に連続してWebサイトのアクセスする為、無意識的に高負荷をかけてしまう事があります。
Ahrefsの場合は、高度に制御されているAhrefsBotが事前に収集したデータを利用する為、自ら対象となるWebサイトに負荷をかける事がありません。また、クローリング済みのデータを利用する為、ワンクリックで直ぐにダウンロードでき、待つこと無く分析に入れるメリットもあります。
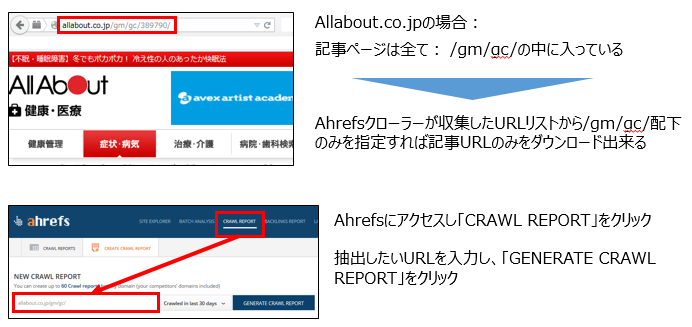
今回は国内最大手のコンテンツメディアサイトAllabout.co.jpを事例として取り上げたいと思います。
Crawl Reportでは、指定したURLの全配下をダウンロード対象として処理します。有料メンバーのプラン毎に抽出できるURL数が決まっており、プラン名「プロフェッショナル」では50,000URLまでダウンロードできます。
できる限り多くの検体を抽出するには、不要な箇所をダウンロード対象から外す必要があります。多くのWebサイトでは、各ページの役割に応じてURLの構造を分けています。Allabout.co.jpの場合は、全ての記事が「/gm/gc/」配下に格納されており、Ahrefsにて「/gm/gc/」以下を指定すれば記事ページのデータのみをダウンロードできます。
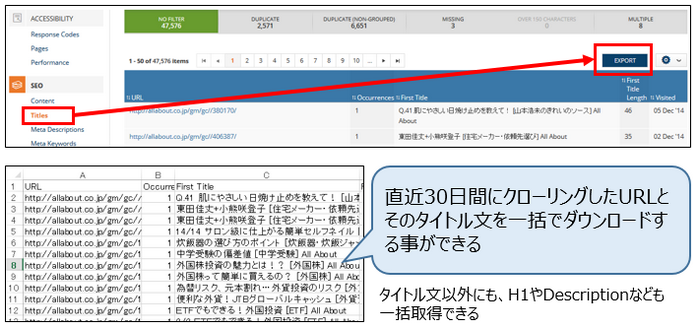
1分程で指定したURL配下のtitle文をダウンロードできます。
メニューバーの「SEO」>「Titles」をクリックし、「Export」をクリックすると、CSV形式でのダウンロードが始まります。直近30日間内にクローリングしたタイトル文を最大5万件ダウンロードできます。
尚、今回使用したツール「Ahrefs:はあくまでも一例です。Web上には様々なクローリングサービスがありますので、対象のWebサイトに負荷を掛けない形で利用を考えてみるのも良いでしょう。
<参考:クローリングサービス>
・Datafiniti – The Search Engine for Data
・80legs
<参考:クローリングの注意点>
・法と技術とクローラと私
・高木浩光@自宅の日記 – 岡崎図書館事件について その1
タイトル文から語句に分割抽出する
大量に取得できたコンテンツページのタイトル文から、サイトもしくはコンテンツページの対策キーワードと思われる単語を抽出していきます。
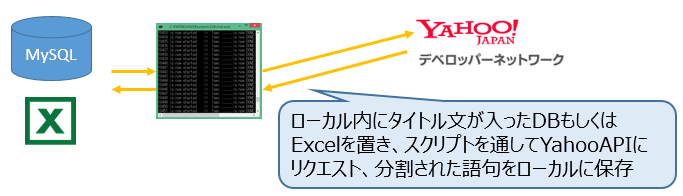
ここでは、Yahoo!APIのテキスト解析を利用します。(利用API:キーフレーズ抽出)
その他にもMeCabやGooラボ日本語文字列解析なども利用できるでしょう。
Yahoo!APIの場合、1日のアクセス数が5万回の上限がある為、大量の解析を行う場合はデータを5万件毎に分けて解析にかけましょう。
APIに情報を投げ、返却する処理の構築方法はいくつか有りますが、大量のデータを分析する場合はPHPやRubyなどで簡単なスクリプトを組んでしまったほうが良いでしょう。
ローカルPC内にデータベースを構築し、その中にタイトル文を一時的に保存し、Yahoo!APIから返却されたキーフレーズ語句を同一レコードのリゾルトカラムに入れるなど自動化する方法は多数あります。
また、キーフレーズ抽出の場合、「キーフレーズの重要度」と定義されたScore値が共に返却されます。この指標をデータフィルターの閾値として見立て、例えば60以下は対象外から外す、といった精査もできます。
<参考>
・PHPExcelで、PHPからExcelを作成・操作する
語句を精査する
形態素解析やキーフレーズAPIなどで自動的に抽出した単語の一部は、調査対象として適切では無いものも含まれます。
ひとつひとつ目視でチェックするわけには行きませんので、ここではGoogleAdwordsの検索ボリュームを利用します。
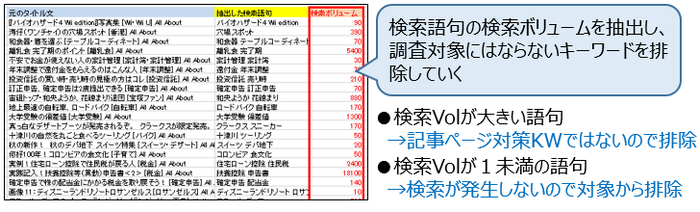
抽出したキーワード案の検索ボリュームを抽出し、Excel上で降順・昇順で並び替えます。
降順の場合、記事ページでは対策し得ないビッグワードが表の上から並びます。あまりにも調査対象となるWebサイトやコンテンツページの内容からかけ離れる単語は削除します。
昇順でソートすると、検索ボリュームが0のワードが並びます。基本的には検索ニーズがあるワードで調査をするべきですので、1未満のキーワードは全て削除します。
この処理を終えたら、後はざっと目視で確認します。
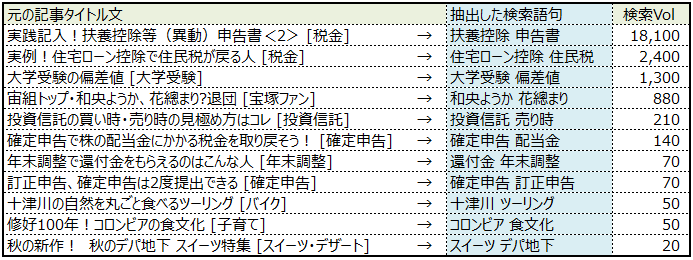
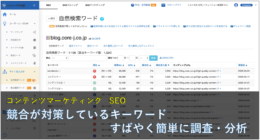
上図は、対象となったAllabout.co.jpのタイトル文(左)と、そのタイトル文から自動抽出した検索語句です。精度としては悪く無く、調査ワードとしては利用できそうです。
Yahoo!APIキーフレーズのScore値や検索ボリュームなど精査時に利用する閾値を調整すれば、もう少し良いキーワードを抽出出来たかもしれませんね。
調査
抽出した対策キーワードを元に対象サイトの調査をしていきます。
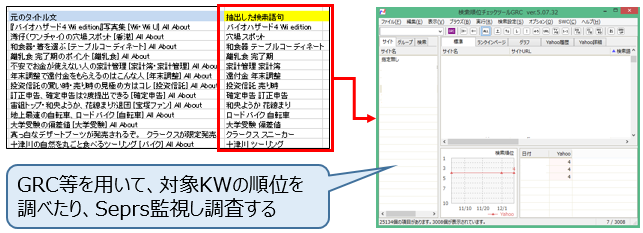
上図の様に、GRCにキーワードを入れて検索順位を計測する事で、Webサイト内に掲載しているコンテンツが検索エンジンから評価されているか調査する事ができます。
又、検索ボリュームとWeb上に公開されているCTRデータを用いて、想定流入数も把握できるかと思います。
その他に、評価されているコンテンツとそうではないコンテンツを文字数や画像の有無など様々な指標を元に比較し、実際のコンテンツ制作に活かせるかもしれません。
まとめ
今回は検索エンジンマーケティングに於ける競合調査のひとつをご紹介しました。
本来はコンテンツページひとつひとつを人の目で確認・理解し、対策キーワードを抽出していくのがベストですが、現実的では無いので、自動化の方法としてご紹介させて頂きました。
●記事ページのURLやタイトル文を抽出する
└AhrefsのCrawl Report
└Web explorer
●タイトル文から検索語句を抽出する
└形態素解析などで文章を単語に分割する
└Yahoo!APIキーフレーズ抽出
●抽出キーワードを精査する
└目視による確認
└検索ボリュームによる絞込
└Yahoo!APIキーフレーズのScore値
●調査分析
└検索順位
└対象サイトとその競合Webサイト
└評価されているページとそうではないページの比較分析