『Webクローリング』はご存知でしょうか? 別の呼び名では、『スクレイピング』とも呼ばれます。
Webクローリングとは、Web上にある情報をクローラー(別名Spider:蜘蛛)というロボットを使ってデータを収集する事を指します。
Googleなどの検索エンジンはもちろんの事、辞書コンテンツを作成&公開するWeb辞書サイトから、大学などの研究機関、情報収集を専門とするアウトソーシング企業まで様々な企業や団体が独自のクローラーを開発し、データ収集を行っています。
このクローリング技術を使う事で、今まで手動で取得していた情報を高速かつ大量に取得する事が出来、より多くのデータから調査や分析を行う事が出来ます。
クローリングの技術とテキストマイニングの技術を合わせる事で、マーケティングに於いては顧客の要望や感想を分析し、より顧客の欲求を理解したり、コンテンツマーケティングの記事案の立案にも利用できます。

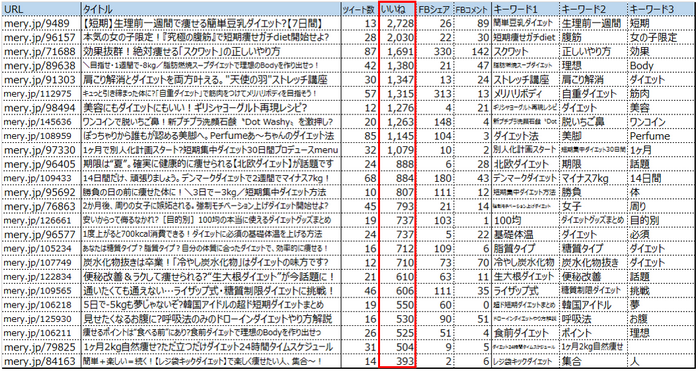
上の表は、キュレーションメディアMery.jpの中で、「ダイエット」に関する記事を取得し、Facebookのいいね数が多いTOP25の記事を抽出したものです。
Facebookのいいね数やURLのツイート数を合わせて抽出する事で、ユーザー(読者)に支持されるコンテンツの「切り口」や「テーマ」を調査し、コンテンツマーケティングのペルソナ設計や記事案に利用する事が出来ます。
又、キーワードをページタイトルや本文からテキストマイニングで分析・抽出しリスト化する事で、見込み顧客が好むコンテンツ内容を分析したり、記事案の立案時ヒントとして利用する事も出来ます。
一定のルールやマナーを守ってクローリングする事で、より深い分析や見込み顧客を理解できます。今回は、クラウド側のWebクローリングサービスを紹介したいと思います。
Portia
Portiaは、PythonのスクレイピングフレームワークScrapyの開発元である、ScrapeHub社のクラウド型スクレイピングサービスです。
インフラの用意やプログラミングの必要が無く、XpathやDOMを指定する必要もありません。ブラウザ越しにスクレイピングしたい箇所やページを指定するだけで、データを自動的に収集してくれます。
実際の操作感は下の動画で確認できます。
金額プランもクローリング数に応じた重量課金制では無く、利用できるクローラー数に応じて固定金額のプランで選ぶことが出来るのもPortiaの良い所です。
Cloudscrape
Cloudscrapeも同じく、ブラウザからクローラーを操作できるSaaSサービスです。
非常に高機能ながら、UI/UXも大変よく出来ており、ある程度の操作方法を覚えるだけで、自由自在にデータ収取が出来ます。
単純なGETでWebページにアクセスする方法はもちろんの事、ログインが必要な箇所へのクローラー回遊やクローラーにクリックアクションを実行させる事も可能です。
尚、クローラーのProxyサーバーは持ち込み制となっており、予め用意する必要があります。共有のProxyサーバーも無料で用意されていますが、数が少なく速度も早く無いので、独自のProxyを用意すると良いでしょう。
無料で利用する事ができ、利用時間によって課金がされる重量課金制のプランになっています。
80legs
80legsは運用歴が長く、Webクローリングサービスとしては老舗的な位置づけにあるSaaSです。
他のサービスの様な気軽さ(抽出した箇所をマウスで指定する)はありませんが、80appsというライブラリが予め用意されており、JavaScriptベースで収集したデータやクローラーの行動を指示することが出来ます。
又、80legsの運営会社Datafinitiは、Webデータを収集し解析するコンサルティング会社であり、プロフェッショナルサービスとしてアウトソーシングの相談も可能。
大量のデータ取得や解析が必要な場合は、コンサルティングサービスを受けてみると良いでしょう。
クローリングする前に注意する事
情報を取得する側は、クローリングを使うメリットは多くありますが、情報を発信している側(Webサイト側)はクローラーによる情報収集はあまり歓迎できる事ではありません。
大量にクローラーからアクセスを受けると、Webサーバーに大きな負荷がかかります。通常、人間によるアクセスではあり得ない程のリクエストを受けると、最悪の場合サーバーが停止してしまう事もあります。
Webクローリングを行う場合は、人間が閲覧する同じスピード・間隔でアクセスし、Webサイト(サーバー)に負荷をかけ無いよう注意しましょう。又、robots.txtや規約の確認もクローリング前に行うようにしましょう。
参考:クローラ作者の逮捕とエンジニアの不安――“librahack事件”まとめ