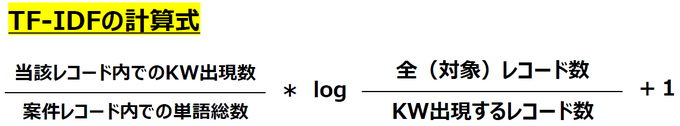昨今、コンテンツを主体としたSEO施策が様々なWebサイトで一定の効果を見せておりますが、レガシィな方法ながらもシステマチックな手法で現在も多くのトラフィックを獲得しているWebサイトは存在します。
その中でもアグリゲーション系のWebサイトは自社内外のデータ資産を「キーワード」で分割・一覧化し、Googleなどの検索エンジンにヒットさせる事で大量のトラフィックを獲得しています。

↑アグリゲーションサイトの代表例
参考:アグリゲーションサイトとは何か?オープンしたTrovit.JPの集客力はどの位?
この「キーワードを抽出する技術」は深層学習や機械学習のブームにより再度注目され、チャットボットなど新しいサービスで利用され始めています。
今回は文字列のデータからデータを抽出し、Webサイト化(一覧ページ化)する為の方法を説明したいと思います。
データ資産からキーワードを発掘し、流入元を作る
多くの商業Webサイトは固定のカテゴリを用いて大量のレコード(データ)を人間が容易く探せるよう分類化しています。これらカテゴリ分類は商品名の代名詞であったり、地域名など一般的かつ検索回数が多いワードで構成されている事が大半です。
しかし、固定カテゴリだけでは検索需要が大きいワードをカバーする事はできません。最近ではスマートフォン等のモバイルデバイスの登場により、ユーザーは何かを知りたいと思った瞬間に情報を探す傾向にあり、検索キーワードの種類の幅は拡大しています。
固有のページを作らず、様々なキーワードを獲得する一つの手法としてサイト内資産(データ)を活用したキーワード型の一覧ページがあります。
参考:ロングテールを獲得するSEO戦術「フリーワード検索ページ」
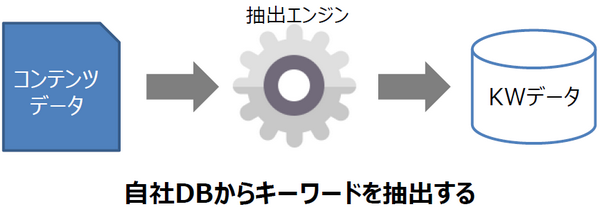
自社内のデータ資産からキーワードを抽出し、一覧ページ化する施策です。
データベース型のWebサイトでは良く用いられる手法であり、他のWebサイトからデータを収集し整理・一覧化するアグリゲーションサイトもこれに該当します。
ここではイメージとして物件賃貸サイトを例に説明したいと思います。
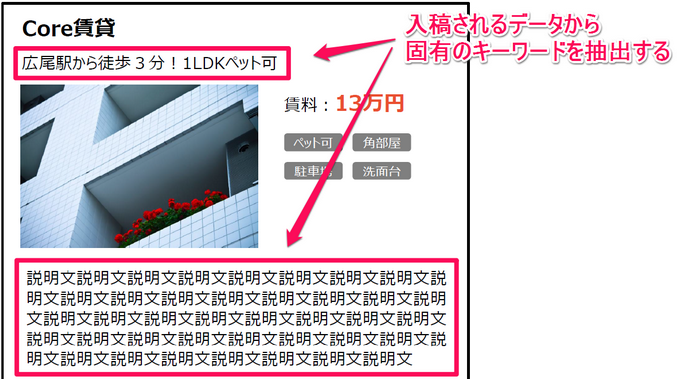
物件比較サイトの場合、町の不動産会社から入稿された物件データのうち、物件名や物件説明文などからキーワードを抽出できると考えられます。
抽出したキーワードと物件レコードはIDで紐付き、キーワードデータを格納しているテーブルに紐づく物件レコード数などを記録していきます。
抽出したキーワードをそのまま一覧ページ化すると、1件しか該当レコードが存在しない一覧ページが大量に発生する形となり、低品質コンテンツの温床となりかねません。キーワード(一覧)を管理するテーブルには該当案件数やステータスなどを記録するカラムも用意します。(n件未満はnoindexを出力などの処理を行なう為)
当ページは単なるフリーワードページ(クエリから全レコードを全文検索し、クエリを含むレコードを表示する検索ページ)とは異なり、特徴語のみがヒットする案件であり、一覧ページの品質(インデックス対象となる指標)を一定の値を上回る場合のみインデックス化を許可するようにします。
合わせて、同義語など意味が略同じワードも1つに統合する仕組みも実装し、類似ページの発生も防ぎます。
参考:タグページの乱立を防ぐ仕組みとシステムの組み方
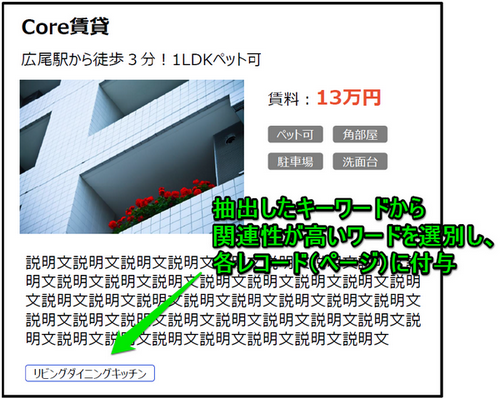
各物件ページには、それぞれの文字列から抽出した固有キーワードのリンクを設置します。
固定カテゴリの一覧ページとは異なる箇所にワード毎の一覧ページを生成します。
configファイルなどにindex対象とする必要最低案件数を設定する事で、自社内のレコード数や抽出キーワードのバリエーションに応じてインデックス範囲を調整できます。
キーワードの自動精査
機械的にキーワードを抽出する場合、人間の目を通さない為、不適切なキーワードも発生してしまいます。
「ます」や「の」など適切な名詞では無い単語や、「家」などと言ったあまりにも意味が大きすぎる単語などがその例として挙げられます。
これら適切ではない単語を半自動的に排除する為には、一定の精査判定値を設ける必要があります。
上記は主に用いられる精査判定値の例です。
出現数や検索需要、該当レコード数、TF-IDF値などを総合的に考慮し、自動抽出ワードを選別していきます。
TF-IDF
「出現数」をベースに抽出語の重み付けをしているケースがありますが、「もの」や「私」など、高頻度で一般的使われる単語が誤って関連性の高いワードとして抽出されてしまう為、出現数だけでは関連性が高いワードを自動選別する事はできません。
そこで利用するのが、TF-IDFです。特徴語を抽出する計算式としてはかなりポピュラーなTF-IDFですが、簡単ながらもある程度の精度を持って特徴語の重み付けを行なう事ができます。
既に自社内の全データからキーワードを抽出している場合、そのキーワードデータを元にTF-IDFを算出します。
検索需要
実際に検索されている文字列は、日本語の検索語としてある程度正しいと考える事ができます。
自動的に抽出した単語の検索需要を調べ、検索需要の有り・無しで適切なワードか否かを判定します。
データ元はサーチコンソールのAPIやキーワードDBサービスのSEOリサーチ・キーワードDBなどを利用する事である程度のキーワードの検索需要を自動的に調べる事ができます。
辞書に登録が無い単語も適切に抽出する
Mecabなどを用いて単語を抽出する場合、辞書の精度や充実度によってキーワードの抽出バリエーションも大きく異なります。
ニッチな業界のDB系サイトや新語が多数出現するニュース系サイトなどは、辞書未登録語も正しく抽出しなければキーワードページの施策は機能しません。
無料で利用できるコーパスから辞書未登録のワードを抽出して辞書を拡充するしたり、機械学習で未知語も適切に抽出するサービスを利用する事で新語の抽出にも対応します。
実際に関連語を文章から抽出してみよう
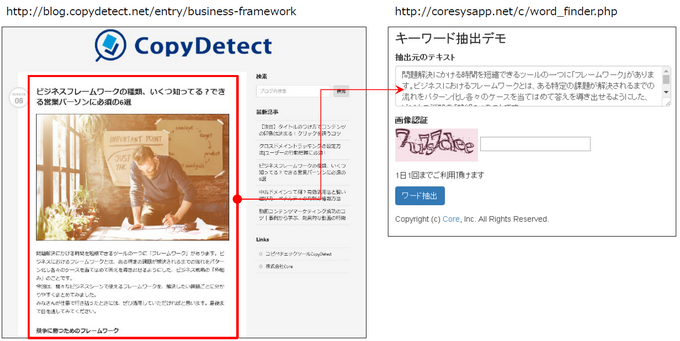
Web上に存在する文章から単語を抽出し、特徴語を選別してみましょう。
今回はテストとして弊社ブログの記事から特徴語を抽出します。
一般的な単語は全て辞書登録した上でMecabで形態素解析し、キーワード毎の重み付けを行っています。
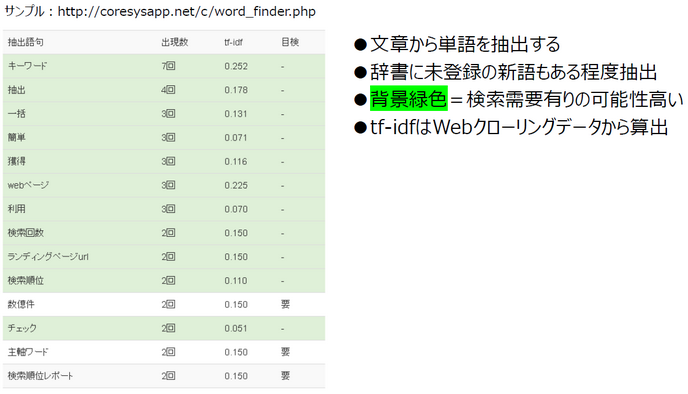
参考:キーワード抽出デモ
このデモページは検索需要が有る可能性が高い単語は背景を緑色で網掛けしています。検索需要が無いワードは「目検」の項目に「要」と表示されます。実際の運用では、この「要」フラグを目視チェックフラグとして設定し、人間による目検チェック対象とします。
尚、TF-IDFはWeb上でアクセスできるコンテンツをクローリングし、辞書を作成・計算している為、極めてニッチな分野の単語は適切に算出できない可能性があります。
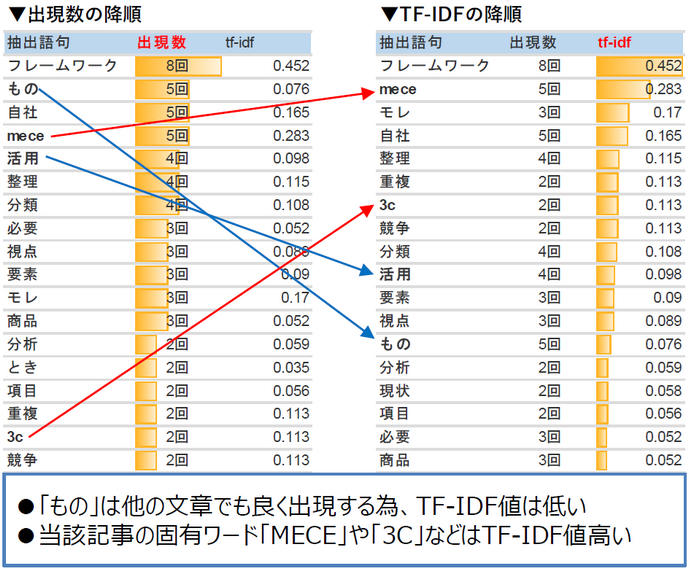
上は対象の記事から特徴語を抽出した例です。
出現数のみでソートした場合、「もの」や「活用」など記事内容の特徴とは言えない単語が関連性高として抽出されてしまいます。
TF-IDFの降順でソートすると、出現数では関連性が低いと判定される「MECE」や「3C」といった当該記事の特徴を表すワードが、関連性高として上位に表示されています。
単に出現数で重み付けするのでは無くTF-IDF値も用いて判定すると、一定の関連性を持った特徴語を簡単に選別できます。
キーワード抽出の利用シーン
アグリゲーションやタグページなどは利用シーンの代表例ですが、キーワードを適切に抽出する事で言語解析系の分析を行なう事ができます。
例えば自社でUGC(ユーザー投稿型サイト)を運営している場合、投稿内容からユーザーの興味関心事を分析し、分析結果からタイムリーに特集コンテンツを企画したり、商品サポートページから投稿されるユーザーのお問い合わせ文章からネガポジ反応を分析し、商品の顧客反応などを分析する事ができます。
最近では機械学習の導入難易度も下がり、大量の文字列データを解析しインサイトを発見できるようにもなりました。
今まで活用しきれなかった自社のデータをキーワードに分解し、解析・加工・分類する事で新しい資産としての価値を生み出す事ができるでしょう。